How to Obtain a dataset for Machine Learning with ProDiscovery?
Wonwhi Ko | May 24, 2018 | 5 min read
“ProDiscovery 3.0 provides insights related to processes.
However, it not only stops at providing insights but can also provide the data necessary for applying Machine Learning.”
Process mining is a valuable tool for Performance Analysis, Process Model derivation, Conformance Checking, and more. While it’s a powerful tool for analyzing historical data, it can yield even more meaningful results when combined with Data Mining. Let me explain how Process Mining and Data Mining can be integrated with some examples.
Researcher A has recently joined the Data Science Team at the major manufacturing company S. As their initial task, A was tasked with analyzing process bottlenecks and extracting critical processes in response to a request from the Process Innovation (PI) department. For this purpose, A found Pro Discovery 3.0 to be a valuable tool.
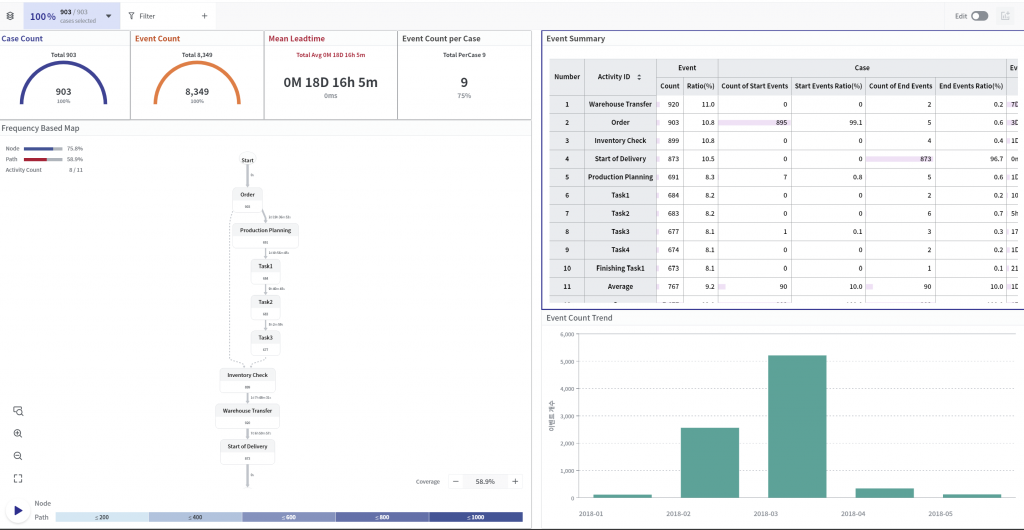
Then, the PI department made another request:
“We now have a sufficient understanding of past processes. We would like to build a predictive system for process innovation using machine learning. We would like to collaborate with you, Researcher.”
Upon receiving this request, Researcher A found themselves in a dilemma.
“It seems like we should use supervised learning… but which algorithm should I use? Well, first, I need to work on setting up the dataset…”
To understand Researcher A’s dilemma, we need to understand supervised learning.
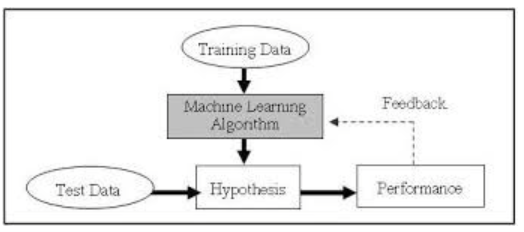
(Source: Wikimedia commons)
Firstly, Machine Learning is the process of finding the function f that best describes the relationship between data X and the corresponding phenomenon Y. Training data is used to train Machine Learning algorithms. Then, among the hypotheses, the function f that best explains the relationship is selected and validated using test data.
Applying this to Researcher A’s situation:
- Data related to the process needs to be obtained.
- This data should be mapped to the actual phenomena. If certain process paths result in poor outcomes, then data related to those process paths would be X, and the poor outcomes would be Y in the mapping.
- Next, the mapped data should be divided into training and validation sets.
- An appropriate Machine Learning algorithm needs to be chosen. In this example, since we are categorizing outcomes into good and bad, decision trees or SVMs, among other algorithms, could be used.
- Depending on the chosen algorithm, after training, the function f is determined. Then, the performance is measured again using the validation data. This process is repeated until the most appropriate function f is found.
Researcher A’s initial concern was indeed related to obtaining data. To build a predictive system, they needed to acquire data related to the process and map this data to actual phenomena. Process Mining becomes a highly valuable tool in this regard. For more details on this topic, you can refer to the previous column on Process Mining and Process Innovation through AI (https://blog.naver.com/prodiscovery/221088085181).
So, how can Pro Discovery 3.0 assist Researcher A? By utilizing the filtering and event data download functions effectively, valuable data can be obtained. By using the filtering function, you can distinguish between processes with short lead time and processes with longer lead time, among other criteria, and construct datasets accordingly.

You can use the event data download feature located in the bottom right corner to obtain information for each process.
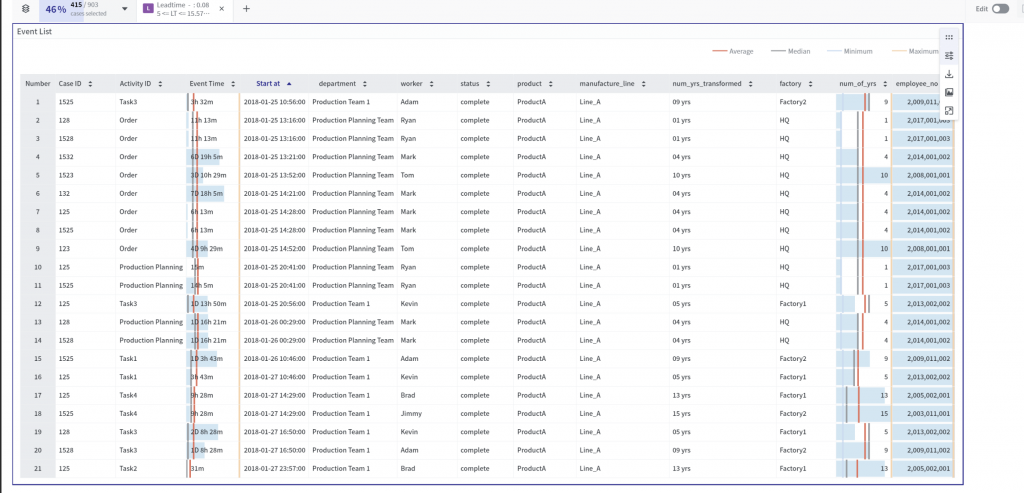
You can obtain the preprocessed dataset from Pro Discovery in Excel format.
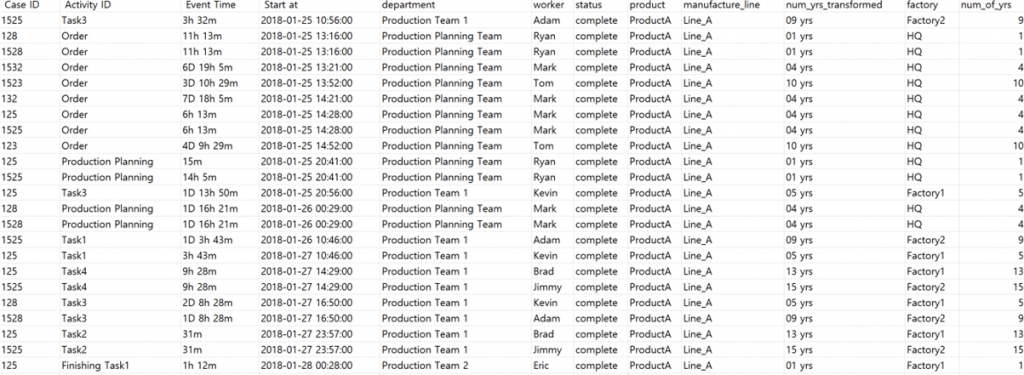
Now, Researcher A has obtained data related to processes.
ProDiscovery 3.0 not only provides insights related to processes but can also supply the necessary data for applying machine learning.