

프로세스 마이닝, 가볍게, 하지만 확실하게 알려드립니다
프로세스 마이닝과 소셜네트워크분석
안녕하세요! 저는 실험적인 방법과 게임을 좋아하는 Process Intelligence 팀의 고재영입니다.
저는 처음으로 프로세스 마이닝을 접하는 분들에게 조금 친숙한 표현으로 설명하고자 이 글을 써보려 합니다. 미리 정리해 말씀드리자면, 프로세스 마이닝은 하나의 공간에서 일어난 여러 이야기들을 모은 로그 데이터로부터 이야기들의 패턴과, 그 이야기에서 어떤 부분이 오랫동안 진행되는지, 어떤 일들이 자주 일어났는지 등 여러 가지 관점으로 바라보고 분석하는 방법론입니다. 여기서 공간은 회사, 웹사이트 내의 구조, 공정 과정 등과 같이 분석하고자 하는 방향에 따라 조금은 정의가 달라질 수 있습니다.
예를 들어 분석을 원하는 곳이 웹사이트 내의 접속 빈도와 한번 접속 당 활동 시간, 구매 여부, 이탈 여부 등이 중요한 쇼핑몰과 같은 업체라면, 하나의 이야기는 각 고객이 한번 접속한 경우에 대한 이용한 로그를 의미하고, 공간은 웹사이트로 인식해 분석을 실시할 수 있습니다.
고객들의 이동경로를 통해, 이용 시간이 긴 구간에 대해 검색어와 연관된 상품을 노출시키는 전략을 구사하거나, 구매 결정까지 이어지지 않은 고객들에 대해 분석하여 페이지를 개선하는 것이 대표적인 예죠.
그렇다면 분석을 위한 로그 데이터는 어떤 것들이 필요한 지 알아보겠습니다. 프로세스 마이닝은 개개인의 이야기들을 모아 어떤 부분이 오래 걸리는지, 일반적으로 어떤 이야기가 흘러가는지, 어떤 과정이 많이 나오는지 등 여러 가지 분석을 위해 세 가지가 필요한데요. 일상적인 대화에서 어떤 것들이 필요한지 같이 알아보겠습니다.
“A : 자기 전 새벽 3시에 과일을 주문했는데, 오늘 아침 5시에 과일이 배송장으로 이동하고, 아까 보니 8시 30분에 우체국으로 이동했다고 알림이 왔어. 지금(9시) 집 앞에 과일이 도착했다고 택배원에게 전화 왔어, 진짜 배송 빠르다.”
이를 하나의 이야기로 본다면 주문자가 과일을 시킨 이야기는 다음과 같이 하나의 표로 정리할 수 있습니다.

이러한 이야기가 많아진다면 다음과 같이 정리할 수 있게 되고, 이렇게 적힌 것들이 서버에 축적되는 로그 데이터입니다.

이때 프로세스 마이닝에서는 이때 하나의 `이야기`를 CaseID, `시간`을 TimeStamp, `누가`를 Resource, `무엇을 했다`를 Activity로 정의(약속) 합니다. 그래서 이러한 케이스들이 쌓인 로그 데이터를 이용해 하나의 맵을 그리게 되면, 다음과 같은 형태로 만들어지게 됩니다.
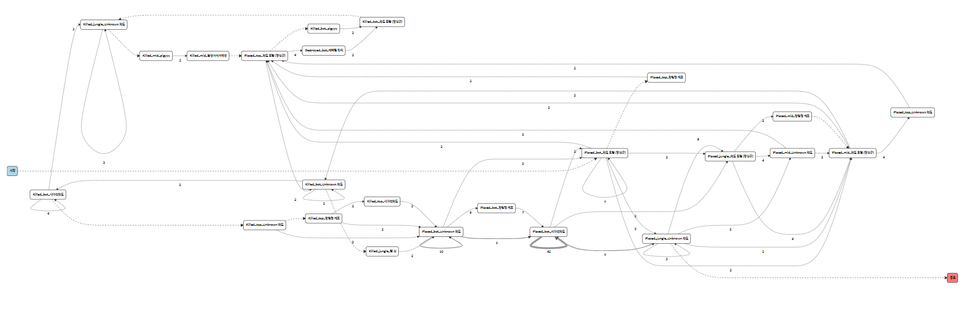
이렇게 만들어진 맵을 통해 어떤 구간이 자주 이용되고, 어떤 부분을 꼭 거치게 되는지, 어떤 부분이 반복적으로 일어나는지에 대해 파악할 수 있고, 일반적인 흐름을 파악할 수 있으며, 문제가 되는 구간이 어디인지 파악할 수 있습니다.
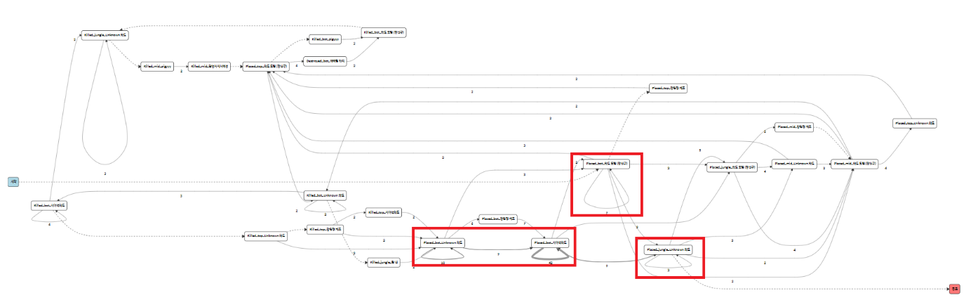
예를 들어 위 그림처럼 패턴이 다양해 문제가 생기는 부분에 대해 패턴이 다양해지지 않도록 프로세스를 개선하여 다음처럼 정규화 시켜 업무 흐름의 복잡도를 줄일 수도 있고,
아래와 같이 반복되는 부분에 대해 RPA를 적용하여 업무의 속도를 개선할 수도 있죠.
즉 프로세스 마이닝은 하나하나의 일들을 모두 기록한 로그 데이터로부터 어떤 문제들이 존재하고, 어디에 해당 구간이 존재하는지를 파악하는데 효과적인 분석방법입니다. 사이코메트리 초능력만큼은 아니지만요 ?

자 그럼 프로세스 마이닝에서의 주요 관점이 프로세스의 흐름의 가시화를 하고 어떤 일이 발생하고 어떻게 흘러가며, 어떤 패턴이 주요 패턴인지 등을 확인한다고만 생각하실 수 있는데요.우리가 이야기를 들을 때는 어떤 일이 일어났는 지만 확인하는 게 아니죠. ‘누가?’ ‘누구에게?’와 같은 등장인물도 중요합니다.
즉. 프로세스에서는 “누가 언제 무엇을 했다.”라는 사건(이벤트)들이 존재하기 때문에, 우리는 등장인물들의 관계 혹은 등장인물들에 대한 일종의 조직도 등을 파악하여 가늠할 수 있습니다. 이 관점을 프로세스 마이닝에서의 소셜 네트워크 분석이라고 합니다. 자, 예를 한번 들어볼게요.회사에서 한 부서에 프로젝트가 열렸다고 해보겠습니다.
“부서장인 A 씨는 팀원 중 선임인 B 씨에게 프로젝트에 대해 설명했고, B 씨는 다른 팀원들 C, D, E, F에게 메일을 보내 결과물을 모아 다시 A 씨에게 보고 했습니다.”
이때 이야기의 순서만 본다면 다음처럼 정리할 수 있고,
(한 일-행위자), (인물 → 인물)의 형태로 다음처럼 표로 정리할 수도 있죠.

이 표를 Resource-Activity Matrix라고 부르겠습니다. 이 표를 보고 (A), (B), (C, D, E, F) 행동에 따라 세 개의 그룹을 분류할 수 있습니다.
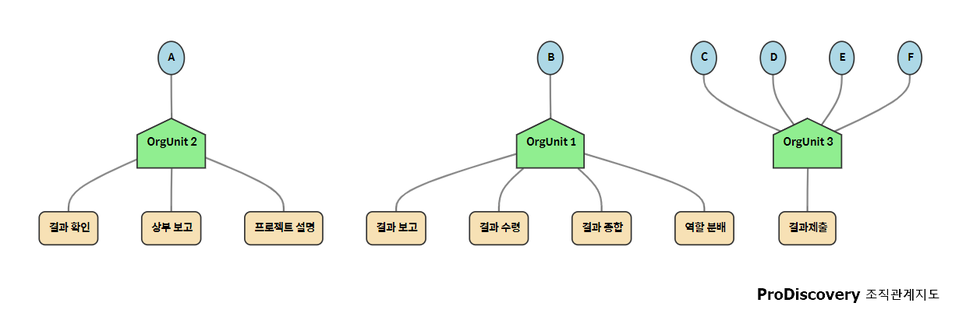
그리고 이 표는 핸드오버 매트릭스(handover of work matrix)라고 부를게요.

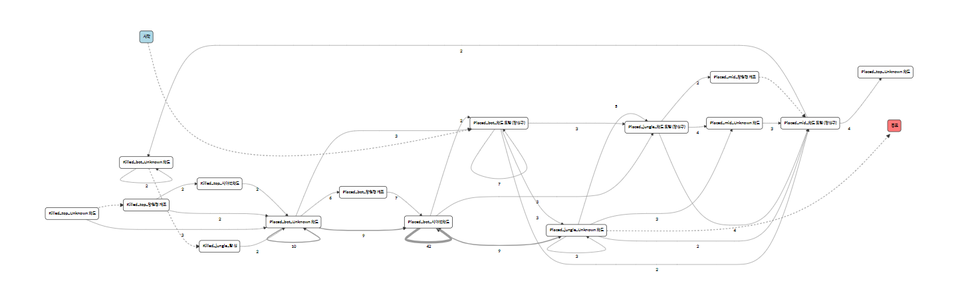
만약 이 표를 그래프의 형태로 나타내면 일의 흐름에 대하여 확인하여, 누가 어떤 역할을 하는지 파악할 수 있습니다. 케이스가 많아져, 데이터가 누적되면 다음과 같은 그래프가 만들어지게 될 것이고, 그래프를 통해 B는 중개자의 역할을 담당하고 있다는 것을 유추할 수 있군요. 오고 간 횟수에 따라 B의 중요도를 크기로 표현된 형태입니다.
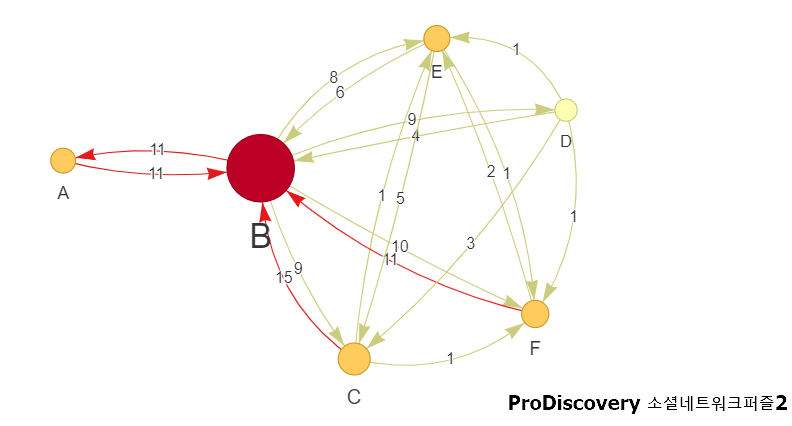
이와 같이 네트워크만 존재한다면 소셜네트워크분석을 통해 해당 그룹에 대해 중요 인물에 대해 파악할 수 있는데요. 표현하고자 하는 관점을 사람이 아닌, 작업으로 바꾸게 되면 프로세스 내에서 서로 연관 깊은 작업들을 묶어 줄 수 있습니다. 다음처럼 말이죠.
이처럼 로그 데이터를 이용해 볼 수 있는 내용과, 그것을 통해 얻을 수 있는 인사이트는 굉장히 많고 다양합니다. 여러분들도 인사이트를 가져갈 수 있으면 좋겠습니다. ?
지금 이 글에서 보인 그래프들은 모두 ProDiscovery의 demo 버전으로 제작한 것입니다. 여기 (https://demo.puzzledata.com/)에 들어가 같이 다른 관점들도 알아볼까요?
