

Causal Footprints를 이용한 적합도 검정 (Conformance Checking)
우리는 앞서 프로세스의 적합도 검정(Conformance Checking)이 무엇인지에 대해 알아보았습니다.(링크) 쉽게 요약하자면, 적합도 검정이란 현실 세계에서 쌓이고 있는 로그(Log) 데이터와 업무 프로세스 상의 이상적인 모델(Model)을 비교하는, 즉, 현실(Real)과 이상(Ideal) 간의 일치도를 비교하는 작업이라 할 수 있습니다.
그렇다면 그 비교를 어떻게 할 수 있을까요?
이번 칼럼에서는 적합도 검정에 대한 방법으로 Causal Footprints를 제시하고자 합니다.
Causal Footprints란?
Causal Footprints란 두 액티비티(Activity) 간의 선후행 관계를 한눈에 나타낸 표라고 할 수 있습니다.
예를 들면,
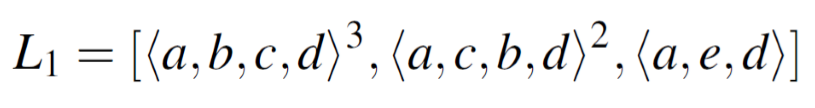
위와 같은 이벤트 로그(=L1)가 존재한다고 가정하겠습니다.
여기서 L1은 이벤트가 발생한 패턴들의 집합이라고 할 수 있습니다. 즉, L1이라는 이벤트 로그는 총 3가지 패턴(L1의 부분집합)으로 이루어져 있다고 말할 수 있습니다. 또한, 부분집합의 상단에 표시된 숫자는 해당 패턴의 발생 빈도를 뜻합니다. 정리하자면, L1은 <a-b-c-d> 패턴 3번, <a-c-b-d> 패턴 2번, <a-e-d> 패턴 1번을 이루어진 이벤트 로그입니다.
이러한 이벤트 로그를 Causal Footprints에 필요한 연산자를 적용하여 표현해보겠습니다.
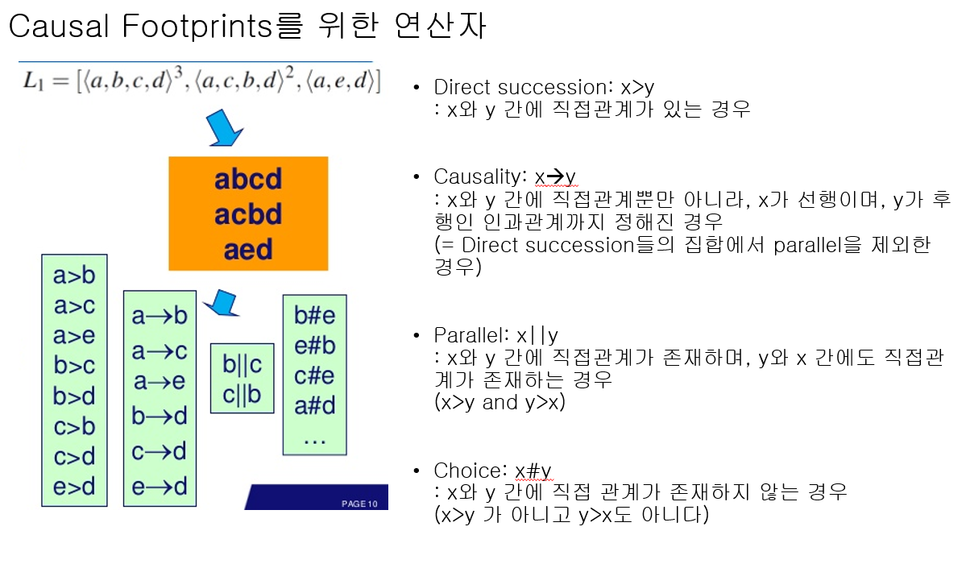
위의 그림은 우리가 관심 있어 하는 L1이란 이벤트 로그를 Causal Footprints 표기에 필요한 관계(Relation) 데이터로 변환시킨 내용을 나타내고 있습니다.
그림에서 x>y 관계는 직접 관계를 나타내고, x->y 관계는 직접 관계 중에서도 선후행이 정해진 인과관계를 나타냅니다. 또한, x||y 관계는 x>y, y>x 두 관계가 공존하는 경우를 나타냅니다. 마지막으로 x#y는 두 액티비티(Activity) 간에 직접 관계가 없음을 나타냅니다.(여기서 > 기호는 대소 관계가 아닌 직접 관계를 나타내는 용도로 쓰입니다.)
이렇게 변환된 데이터를 Causal Footprints로 나타내면 아래와 같습니다.

Causal Footprints를 이용한 적합도 검정(Conformance Checking)
우리는 위에서 Causal Footprints에 대해 알아보았습니다.
그렇다면 Causal Footprints를 이용한 적합도 검정은 어떻게 하는 걸까요?
앞서 설명한 것과 같이, 적합도 검정이란 현실 세계에서 쌓이고 있는 로그(Log) 데이터와 업무 프로세스 상의 이상적인 모델(Model)을 비교하는, 현실(Real)과 이상(Ideal) 간의 일치도 비교 작업이라 설명드렸습니다.
여기서, 현실과 이상을 비교하기 위해 쓰이는 것이 Causal Footprints입니다.
즉, 현실을 대표하는 로그(Log) 데이터와 이상을 대표하는 모델(Model)을 각각 Causal Footprints로 변환한다면 두 데이터 간에 비교가 가능해집니다.

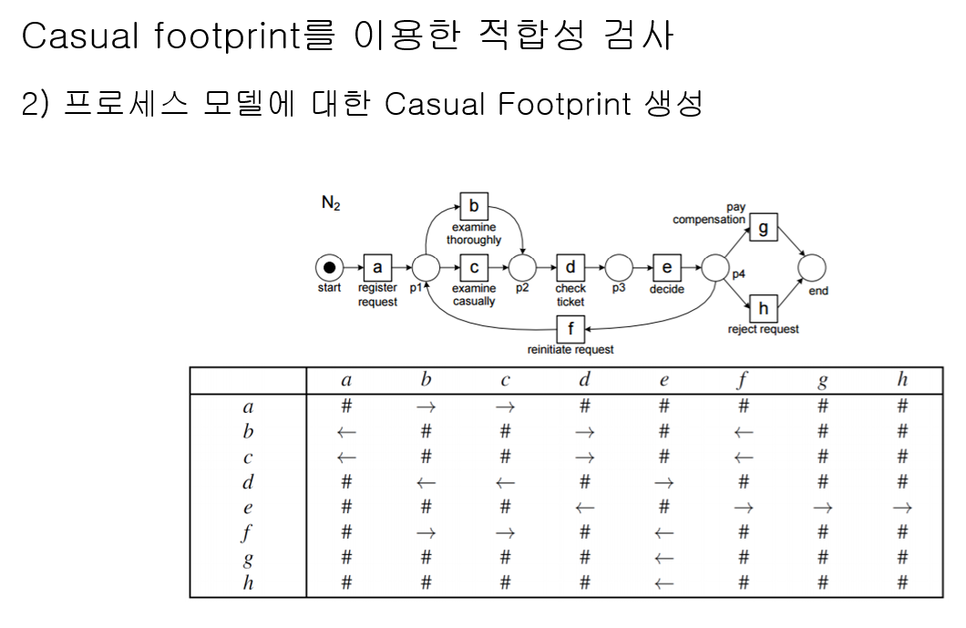
마지막으로, 변환한 두 Causal Footprints의 일치도를 구하면 우리가 하고자 했던 적합도 검정(Conformance Checking)의 적합성(Fitness)을 나타내는 지표를 얻을 수 있습니다.
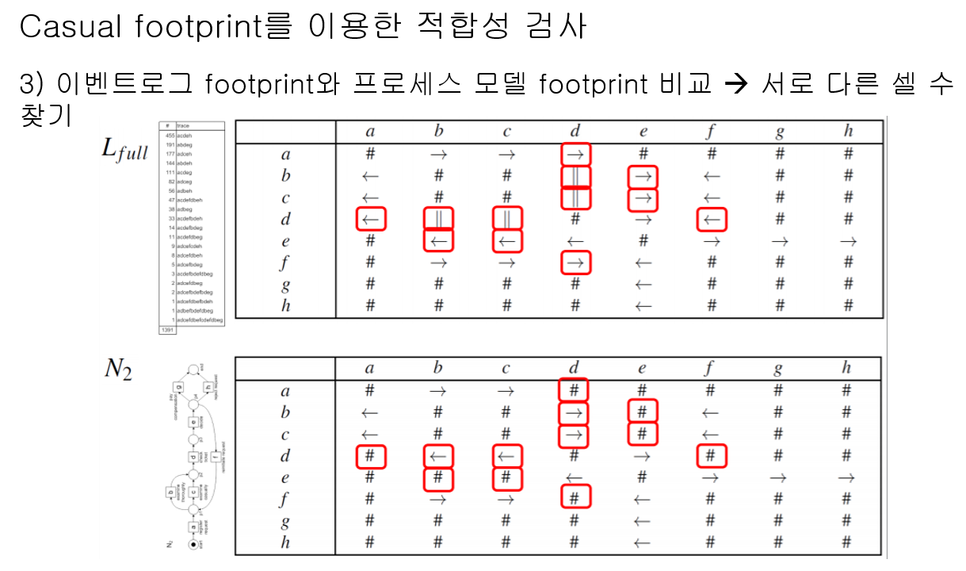

검정 결과, 0.8125라는 적합도(Fitness)가 나왔으며, 이는 내가 보유하고 있는 로그(Log) 데이터에 대해, 비교하고자 하는 모델(Model)이 81.25% 적합하다고 설명할 수 있습니다.
한계점
모든 것이 만능일 수 없듯이, Causal Footprints를 이용한 적합도 검정(Conformance Checking)에도 Causal Footprints를 사용하는 것에서 오는 한계가 존재합니다.
1. 각 케이스(Case)를 통해 얻을 수 있는 프로세스 패턴(Pattern) 정보에 대한 반영이 미흡하다.
A. Causal Footprints라는 것이 결국, 액티비티와 액티비티 간의 직접적인(Direct) 관계를 표현하는 표이기 때문에 프로세스 마이닝에서 중요하다고 할 수 있는 프로세스 패턴(Pattern)에 대한 정보는 간접적으로 반영되게 됩니다.
2. 빈도수에 따른 주요 프로세스에 대한 영향을 고려할 수 없다.
A. Causal Footprints의 특성상 빈도수에 대한 고려가 없기 때문에, 주요 흐름에 대한 관계가 무엇인지 알 수 없습니다.
우리는 오늘 Causal Footprints를 이용한 적합도 검정(Conformance Checking)에 대해 알아보았습니다.
Causal Footprints를 이용한 적합도 검정(Conformance Checking)은 한계점도 분명 존재합니다.
또한, 토큰 리플레이를 기반으로 한 적합도 검정(conformance checking based on token-based replay), 정렬 기반 적합도 검정(Alignment-based conformance checking) 등 다양한 적합도 검정 방법도 존재합니다.
그럼에도 불구하고, Causal Footprints를 이용한 적합도 검정(Conformance Checking)은 가장 직관적(intuitive)이고 강력한 적합도 검정이라 할 수 있습니다.
현재 PuzzleData에서는 이러한 이론을 바탕으로, 적합도 검정(Conformance Checking) 기능 개발이 예정되어 있으며, ProDiscovery 제품에 반영되어 만나보실 수 있을 예정입니다.
긴 글 읽어주셔서 감사합니다.
[참고]
Coursera – Process Mining: Data science in Action( Wil van der Aalst, week2, week4)
(https://www.coursera.org/learn/process-mining)
