

Heuristic Mining이란?
heuristic mining의 의미를 정확히 알고 있다면,
더 정확하고 전문적인 map을 그리는 것이 가능해집니다.
Heuristic mining은 다른 process map들에 비해 꽤나 복잡합니다. Threshold의 종류도 많고, 이에 따라 각 threshold가 어떤 의미를 가지고 있는지도 이해하기가 어렵기 때문에 heuristic mining의 의미를 정확히 알고 분석을 하는 것은 쉽지 않습니다. 하지만 heuristic mining의 의미를 정확히 알고 있다면, 더 정확하고 전문적인 map을 그리는 것이 가능해집니다.그렇다면, ProDiscovery에서의 heuristic mining에 대해 구체적으로 알아보겠습니다.
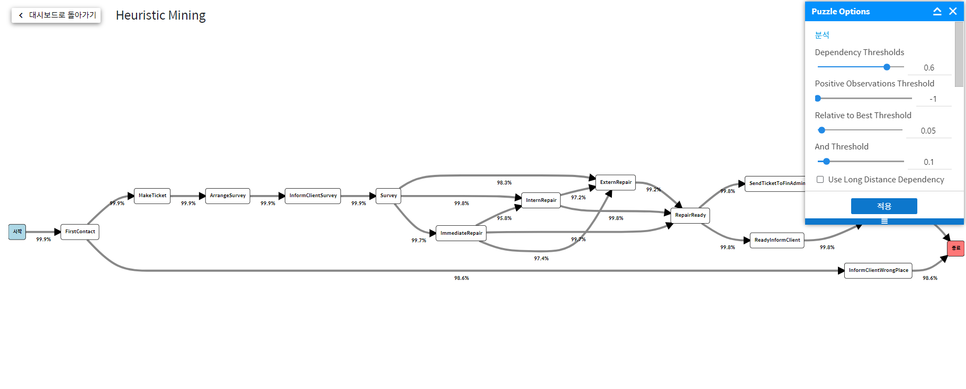
우선 Heuristic mining이란, 프로세스 마이닝의 가장 기본이 되는 알고리즘인 Alpha algorithm을 발전시킨 형태로, 기본적으로 frequency(이벤트와 flow의 빈도)와 이를 바탕으로 한 dependency를 고려하여 맵을 생성합니다. Heuristic mining은 알파 알고리즘과는 다르게 빈도수를 고려할 수 있고, single activity, 즉 프로세스가 두 단계 이상 존재하지 않고 하나의 작업으로만 구성된 케이스를 생략할 수 있다는 장점을 가지고 있습니다.
Heuristic mining map이 만들어지는 과정은 다음과 같습니다. 우선, dependency matrix를 생성합니다. Dependency는 위에서도 말했듯이 heuristic mining을 구성하는 가장 기본이 되는 값입니다.
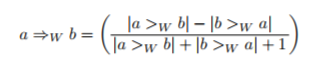
Dependency가 양수이면 그 방향으로의 이벤트가 더 많은 것이고, 음수이면 반대 방향으로의 이벤트가 더 많은 것입니다. Dependency의 절댓값이 클수록 더 강한 관계를 가지고 있다고 볼 수 있습니다. 다음으로, 이 dependency matrix를 바탕으로 petri net을 생성합니다. 그러면 가장 기본적인 heuristic map이 생성되고, 이를 바탕으로 threshold를 조절함으로써 map을 원하는 대로 조절할 수 있습니다.
그렇다면, 이 threshold의 종류에는 어떤 것이 있을까요? ProDiscovery에서는 총 4개의 threshold를 사용하고 있습니다.
첫 번째 threshold_dependency threshold
각 경로의 dependency 값을 바탕으로, dependency가 설정한 threshold보다 높은 경로만을 map으로 표시합니다. 이 threshold를 통해 dependency 필터링이 가능합니다.
두 번째 threshold_positive observations threshold
두 액티비티 사이의 이벤트 수의 차이가 설정한 threshold보다 많은 경로만 표시합니다. 이를 통해 갑자기 프로세스가 분개 되는 경우나 합쳐지는 경우 등 두 작업 사이의 이벤트 수의 차이가 큰 것을 필터링하는 것이 가능해집니다.
세 번째 threshold_relative-to-best threshold
Map 내의 모든 경로의 dependency 중 가장 큰 maximum dependency 값과 각 경로의 dependency 값의 차이가 설정한 threshold보다 작은 경로만 표시합니다. 이를 통해 절대적인 dependency 값 만을 필터링하는 것이 아니라 각 map의 특성에 따른 dependency 필터링이 가능해집니다.
네 번째 threshold_ AND threshold
AND threshold를 아래 식에 따라 계산하고, 설정한 threshold보다 값이 높으면 AND, 낮으면 OR로 flow를 취급합니다.
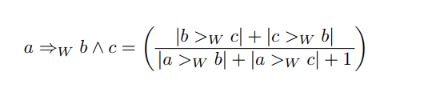
지금까지 heuristic mining을 어떻게 구성하고, 이 map을 사용자가 원하는 대로 조절하기 위해서는 어떤 값을 이용하고 어떻게 이용해야 하는지를 알아보았습니다. Heuristic mining을 통해 기존의 frequency만을 기반으로 한 프로세스 맵에서 벗어나, frequency와 dependency를 함께 고려하여 사용자의 입맛에 더 잘 맞는 프로세스 맵을 분석하실 수 있기를 바랍니다.
