

프로디스커버리(ProDiscovery) 시스템 구성 소개
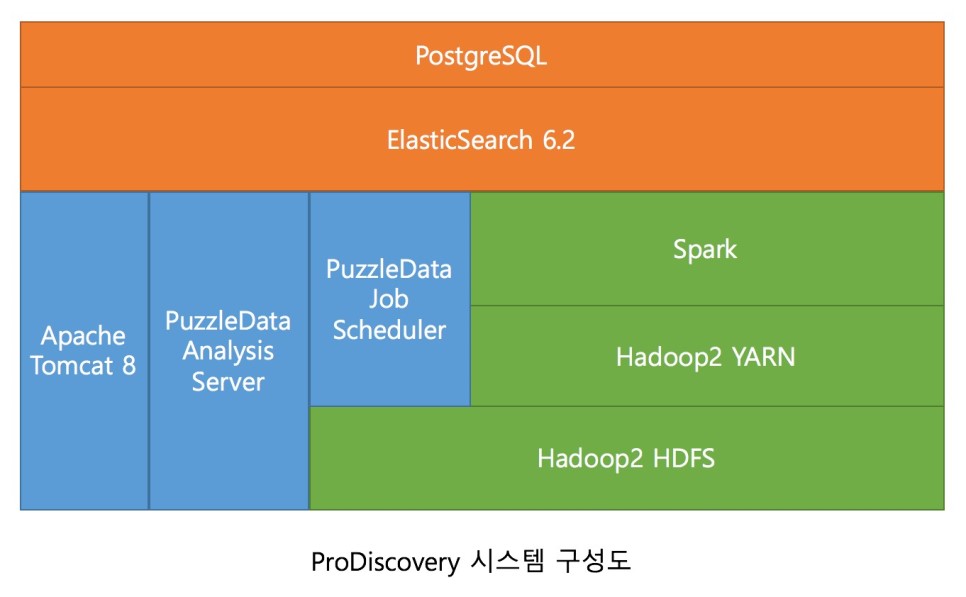
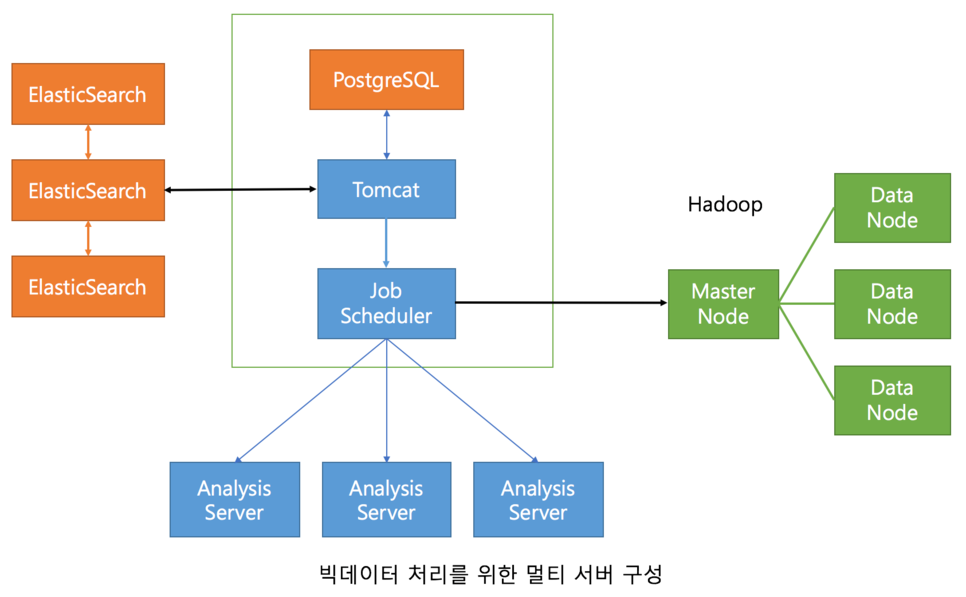
프로디스커버리(ProDiscovery)는 대용량 데이터 처리 및 빠른 데이터 처리를 위해 다소 복잡한 시스템 구성을 하고 있습니다. 기본적으로는 이 모든 구성이 단일 서버에서 이루어지도록 하고 있으나 대용량 데이터 처리 시에는 서버를 분리해서 여러 대로 구성해야 합니다.
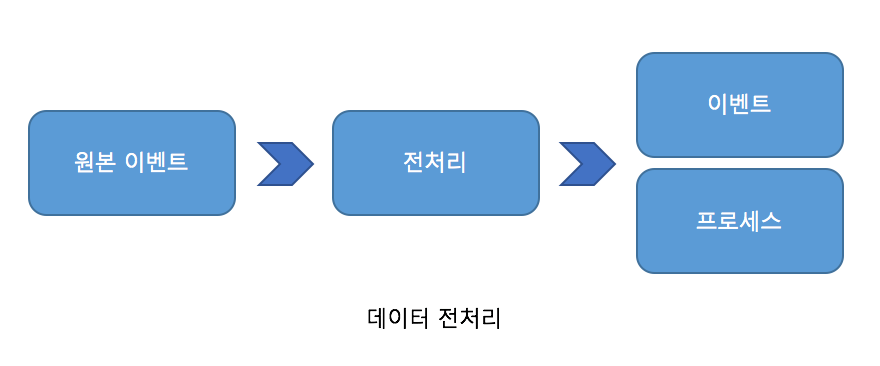
프로디스커버리로 분석을 하기 위해서는 사용자가 가진 원본 데이터를 분석 수행이 가능한 형태로 가공하는 작업을 해야 합니다. 이를 내부적으로 [데이터 전처리]라고 부르고 있습니다.
데이터 전처리를 위해서는 많은 양의 데이터를 처리할 수 있어야 하며 이를 위해 빅데이터 처리 시스템인 하둡과 스파크를 활용하고 있습니다.
각 시스템 별 용도에 대해 설명하겠습니다.
Hadoop HDFS
데이터 저장소로서의 역할을 수행합니다. 이곳에는 사용자가 등록한 원본 이벤트 파일(CSV) 이 저장됩니다. 또는 데이터 수집 모듈을 통해 실시간 데이터를 저장하기도 합니다. 또한 Spark를 통한 전처리 작업 수행 시 여러 대의 서버로 데이터 처리를 가능하도록 도와줍니다.
Hadoop YARN
서버의 자원을 관리하는 역할을 합니다. 하둡 시스템으로 구성된 여러 서버 자원들을 모니터링하고 있으며 요청이 들어오면 전처리 작업을 자원에 분배해서 처리합니다.
Spark
원본 이벤트 데이터로부터 분석 가능한 데이터를 생성해내는 작업을 실질적으로 수행합니다. 실제 전처리 관련 코드들은 이곳에 작성되어 작업이 이루어집니다. 하둡과 연계하여 메모리 기반으로 빠른 분석을 수행합니다.
Job Scheduler
데이터 전처리 작업 및 분석 요청 작업을 관리합니다. 데이터 전처리 작업이 요청되면 스파크로 작업을 보내고 모니터링하게 됩니다.
분석 요청 작업은 실제 퍼즐들에서 사용하는 알고리즘 계산 작업에 대한 요청을 관리하게 됩니다.
Analysis Server
각각의 퍼즐들에서 요청하는 알고리즘 계산 작업을 수행하게 됩니다.
Tomcat
웹서버로서 단순히 브라우저의 요청을 받고 응답을 돌려주는 역할을 수행합니다. 화면에 보여지는 요소들의 관리 및 처리를 하게 됩니다.
ElasticSearch
데이터 전처리를 통해 생성된 이벤트/프로세스 관련 분석 가능한 데이터를 저장합니다. 메모리 캐시 기반으로 매우 빠른 속도의 query 결과를 보여줍니다.
PostgreSQL
실제 데이터를 제외한 폴더 정보, 데이터 집합 정보, 대시보드 정보, 회원정보 등 모든 메타 데이터를 관리합니다.
위와 같이 프로디스커버리는 빅데이터 기반의 효율적인 데이터 처리를 위해 이미 많은 사용자 및 기업에 의해 검증된 여러 오픈소스 시스템 위에 자체 개발한 알고리즘들을 적용하여 수행되고 있습니다.
