

정확한 프로세스 모델을 측정하는 기준은?
이벤트 로그로부터 정확한 프로세스 모델을 도출하기 위해 고려해야 할 점은 무엇일까요?
프로세스의 특성과 이벤트 로그에 맞는 적절한 알고리즘을 적용하는 것이 중요하지만 오늘은 좀 더 일반적인 사항에 대해 생각해 보겠습니다.
프로세스 모델의 품질을 측정하는 4가지 기준은 Fitness, Generalization, Simplicity, Precision입니다.
좋은 프로세스 모델을 발견하기 위해서는 이 4가지 기준 사이에서 균형을 잘 유지해야 합니다.
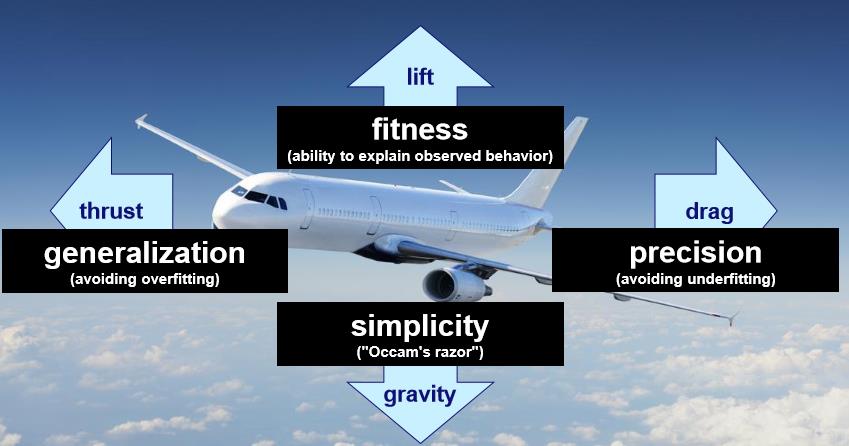
Fitness(적합도)는 관찰된 이벤트 로그를 얼마나 잘 설명할 수 있는지를 나타냅니다. Fitness가 높을수록 모든 이벤트 로그의 경로를 표현하기 때문에 데이터 집합을 잘 설명할 수 있으나 수많은 경로가 프로세스 모델에 나타나게 되어 프로세스 모델이 복잡해지게 됩니다.
Generalization(일반화)은 Overfitting을 피하는 것입니다. Overfitting된 모델은 모델 추출 대상이 되는 데이터(이벤트 로그)에 대해서는 정확도가 높으나 동일 프로세스에서 추출한 다른 데이터 집합에 대해서는 정확도가 낮고, 높은 오류율을 보여주게 됩니다. 따라서 Generalization 수준이 높을수록 다른 데이터에 적용했을 때의 적중률(설명 정도)이 높아져서 프로세스 모델을 다른 데이터에 적용하기가 좋습니다. 하지만, 지나치게 Generalization이 높을 경우 대상 데이터 집합에 대한 프로세스 모델 적중률만 높아지지 프로세스에 대한 의미 있는 정보를 전달하지 못하는 문제가 발생합니다.
Simplicity(단순화)는 프로세스 모델을 단순하게 만드는 것입니다. 프로세스 모델이 단순할수록 쉽게 이해하고 한눈에 프로세스를 파악할 수 있으나 적합도가 떨어지게 됩니다. 적합도가 떨어지면 추출한 프로세스 모델로 설명할 수 없는 이벤트 로그가 많아지게 됩니다.
Precision(정확도)은 Underfitting을 피하는 것입니다. Underfitting된 모델은 Overfitting과 달리 모델을 단순화하여 공통 경로만 표현하게 되어 프로세스를 정확하게 설명할 수 없게 됩니다. Precision이 높을수록 기존 데이터에 대해 정확하게 설명할 수 있으나 지나치게 높을 경우 다른 데이터 셋에 대한 오류율이 증가하는 문제가 생깁니다.
4가지 품질 특성을 보면 Fitness와 Simplicity, Generalization과 Precision은 서로 반대되는 특성을 가지고 있습니다. 즉, Fitness가 너무 높으면 Simplicity가 낮은 문제가 생기고 Generalization이 높으면 Precision이 낮은 문제가 생기게 됩니다.
Overfitting과 Underfitting 예제를 통해 좀 더 살펴보도록 하겠습니다.
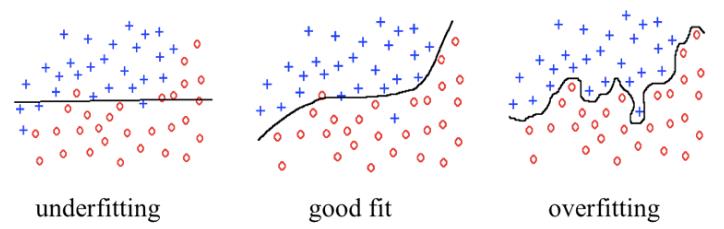
[그림 2]에서 볼 수 있듯이 Underfitting은 데이터 분류 기준을 단순하게 구할 수 있으나 새로운 데이터 집합을 Underfitting된 모델에 대입하면 의미 있는 결과를 얻기가 힘듭니다. 이에 반해 Overfitting은 모든 데이터를 정확히 분류하고 있으나 데이터의 특성을 일반화시킬 수 없습니다.
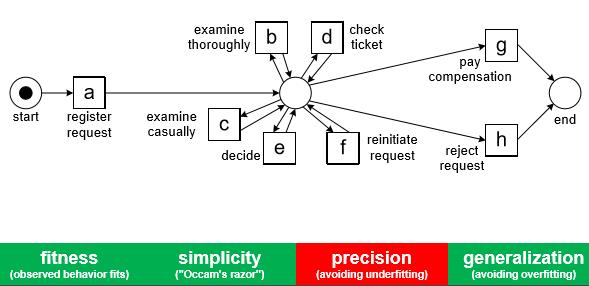
[그림 3]의 경우 모든 경로를 표현 가능하여 Fitness 만족, 다른 모델에도 적용 가능하여 Generalization 만족, 모델도 간단하여 Simplicity도 만족하지만 실제 프로세스가 어떻게 수행되는지 설명해 주지 못해 도출된 프로세스 모델에서 유의미한 정보를 얻을 수 없습니다. 즉, 모델이 Underfitting되어 Precision 조건을 만족시키지 못합니다.
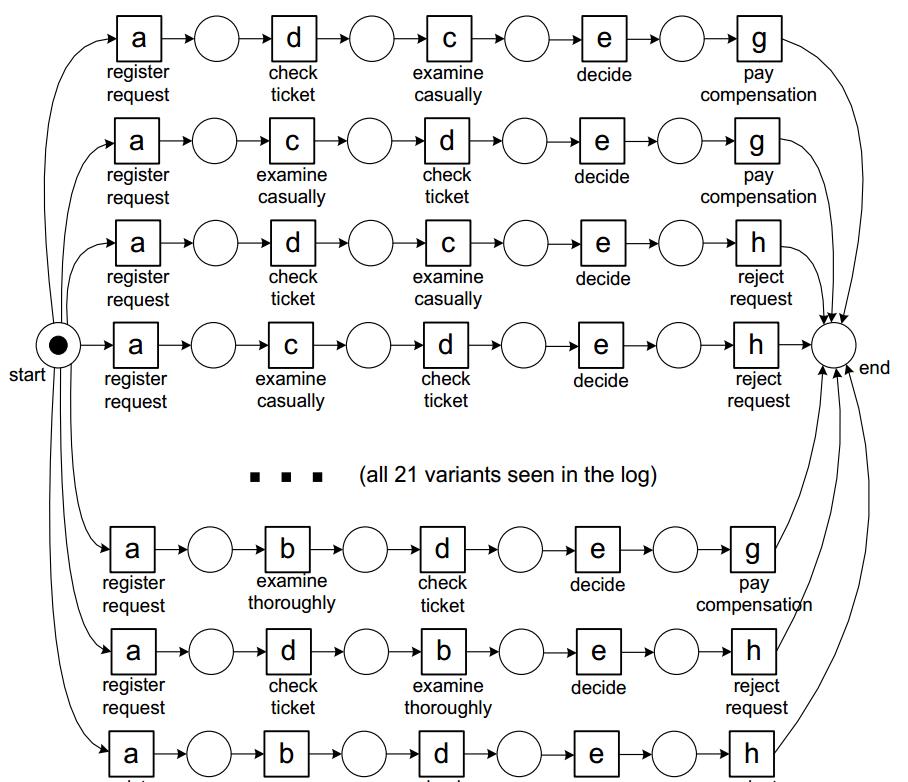
[그림 4]는 관찰된 이벤트 로그를 모두 나열한 프로세스 모델입니다. 이렇게 할 경우 모델을 도출할 때 사용한 이벤트 로그의 프로세스 패턴을 모두 나타내어 Fitness와 Precision은 만족하나 Simplicity와 Generalization은 만족하지 않습니다. Overfitting된 모델도 프로세스 모델에서 유의미한 정보를 얻을 수 없습니다.
이상과 같이 Fitness, Generalization, Simplicity, Precision 4가지 기준을 잘 조화시켜야 정확한 프로세스 모델 도출이 가능합니다.