


지난번 포스팅을 통해서 프로세스 시뮬레이션 수행을 위한 정보 도출 과정을 상세하게 소개했습니다. 이번 포스팅에서는 도출된 정보를 바탕으로 시뮬레이션이 어떻게 작동하는지, 그리고 Prodiscovery 3.0의 시뮬레이션 분석 대시보드를 간략히 소개하겠습니다.
1) 시뮬레이션 수행
데이터로부터 다양한 정보를 도출함으로써 시뮬레이션 수행을 위한 준비가 끝났습니다. 하지만 기존 데이터와 그대로 시뮬레이션을 한다면 별 의미가 없겠죠? 이제는 정말 분석하고 싶었던 상황을 시뮬레이션 모델에 적용해야 합니다. 예를 들어, 병원 프로세스인 경우 작업자인 의사 수를 늘려볼 수 있고, 하루에 방문하는 환자의 수를 늘려볼 수도 있습니다. 또는, 아직 모든 진료 프로세스를 완료하지 않은 환자에 대하여 진료를 마치기까지 걸리는 시간을 예측해 볼 수도 있습니다. 이렇듯 시뮬레이션에서는 프로세스 개선을 위한 다양한 상황을 가정할 수 있습니다. 사용자가 원하는 상황에 관련된 옵션을 변경한 후, 이제 시뮬레이션은 가상의 이벤트 로그를 생성하기 시작합니다.
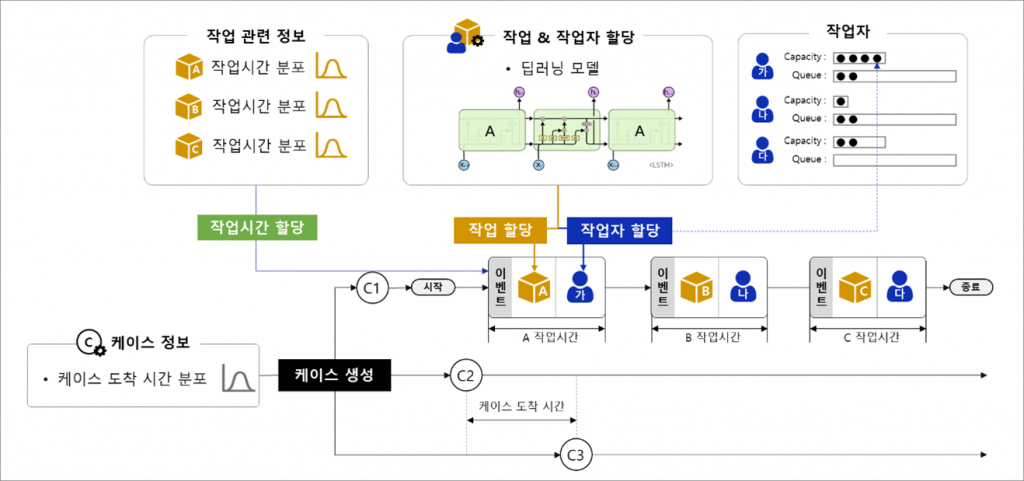
[그림4] 시뮬레이션 엔진 구조
[그림4]는 시뮬레이션 엔진이 로그를 생성하는 과정을 나타낸 그림입니다. 우선 가상의 케이스를 생성합니다. 이때 각 케이스 간 간격은 앞서 데이터로부터 도출한 케이스 도착 시간 분포를 활용하여 랜덤하게 할당합니다. 다음으로 가운데 위쪽에 위치한 딥러닝 모델이 각 케이스가 수행할 작업과 작업자를 할당하면, 작업시간 분포로부터 해당 작업에 대한 작업시간을 랜덤하게 생성합니다. 앞서 배정된 작업자의 작업 리스트에는 일이 쌓이고 업무수행능력(Capacity)을 넘어가게 되면 대기열(Queue)에 쌓입니다. 이와 같은 과정을 반복하여 모든 케이스가 모든 작업들을 종료할 때까지 시뮬레이션을 수행합니다.

[그림5] 프로세스 시뮬레이션 예시 (gif)
시뮬레이션이 진행되고 있는 모습을 시각화하여 볼 수도 있습니다. [그림5]는 시뮬레이션이 수행하는 과정을 보여주는 애니메이션입니다. 검은 동그라미는 하나의 케이스를 나타내고, 마름모는 프로세스 내 작업을 의미합니다. 케이스가 일렬로 쌓이는 것은 해당 작업을 하기 위해 케이스가 대기하고 있는 것입니다. 특정 작업에 대기가 쌓이는 이유는 해당 작업을 수행하는 작업자의 업무수행능력보다 더 많은 일이 몰려왔기 때문입니다.
2) 결과 비교 분석
시뮬레이션을 수행하여 가상의 로그가 생성되었다면, 이제 기존 데이터와 비교하여 얼마나 효과가 있었는지 분석해야 합니다. [그림5]는 Prodiscovery 3.0에서 개발중인 시뮬레이션 분석 대시보드입니다. 차트 내에서 파란색으로 표시된 글자 및 그래프들은 모두 기존 데이터에 대한 정보를 나타내고, 반대로 분홍색은 시뮬레이션 로그에 대한 내용을 의미합니다. 대시보드를 통해 두 데이터 간 프로세스 맵, 케이스 또는 이벤트 개수, 시간(leadtime), 비용, 작업시간 등 다양한 KPI를 한눈에 비교 분석할 수 있습니다.
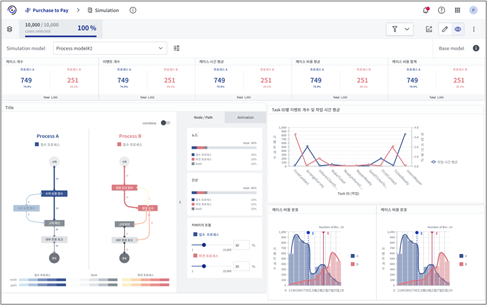
[그림5] Prodiscovery 3.0 시뮬레이션 시나리오 대시보드 예시
지금까지 프로세스 시뮬레이션에 대한 전반적인 방법론을 소개하였습니다. 이 글을 다 보셨다면 프로세스 시뮬레이션이 어떻게 작동하는지 큰 그림을 볼 수 있을 것이라 생각합니다. 본 포스팅에 언급된 모든 내용은 Prodiscovery 3.0에서 제공할 프로세스 시뮬레이션에 구현되어 있으며 앞으로 다양한 프로세스 개선에 활용될 것이라 기대하고 있습니다. 그럼 많은 관심 부탁드립니다!
