

프로세스 마이닝을 위한 데이터 전처리 도구 아파치 스파크
데이터 전처리는 왜 필요할까요?
우리가 일상생활 행하는 많은 행동들이 데이터로 변환 될 수 있습니다. 하루에 화장실을 몇 번 가는지, 밥을 먹을 때 젓가락을 몇 번 식탁에 내려놓는지 혹은 일을 하며 얼굴을 몇 번 만지는지 등이 모두 가능합니다.
이러한 데이터를 수집하는 과정에서 다양한 일이 벌어질 수 있는데, 첫 번째로, 컴퓨터가 자동으로 데이터를 수집한다면, 컴퓨터의 오류로 데이터가 비정상적으로 커질 수 있고, 혹은 반대로 너무 작아질 수도 있습니다. 이러한 데이터들을 잡음 데이터라고 표현합니다.
두 번째로, 데이터가 있어야 할 곳에 데이터가 존재하지 않고 공백으로 남겨져 있을 수도 있습니다. 예를 들어 우리가 설문 조사를 할 때 귀찮아서 대충 하다가 한 칸을 넘기는 그런 때이죠. 이런 경우를 불완전 데이터라고 합니다.
세 번째로는 잘못된 정보의 기입으로 모순된 데이터가 들어올 수 있습니다. 예를 들어 생년월일과 나이가 불일치하는 경우입니다. 이러한 경우는 모순된 데이터라고 부릅니다.
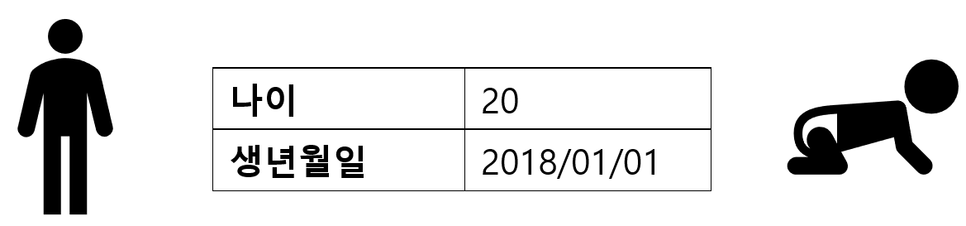
불완전하고 잡음이 있고 모순된 데이터로 프로세스 마이닝을 한다면, 우리에게 필요하지 않은 정보들로 인해 필요한 정보들을 찾는데 어려움 있을 수 있습니다. 예를 들면 상위 10개 데이터를 보고 싶은데 잘못된 잡음 데이터로 인해 상위 10개의 정보가 잘못되어 있을 수도 있고, 하위 10개를 보려 할 때, 공백으로 남겨진 데이터 때문에 하위 정보들이 다 빈칸일 수도 있습니다. 그렇게 된다면 데이터 분석가는 오류 확인을 위해 많은 시간을 투자해야 합니다. 특히, 프로세스 마이닝에서는 케이스 개념이 중요한데, 전처리를 하지 않으면 케이스들이 중구난방으로 퍼지게 되므로 전처리는 프로세스 마이닝에서 매우 중요한 단계라고 할 수 있습니다.
데이터 전처리는? 아파치 스파크!
빅데이터 영역에는 좋은 툴들이 많지만 그중 데이터 전처리에 가장 좋은 툴은 Apache spark라고 자부할 수 있습니다.
스파크의 가장 큰 장점은 속도입니다. 기존의 하둡(Hadoop)을 이용하여 전처리 실행 시 파일을 읽고 쓰는 IO(Input Output) 작업으로 의미 없는 작업이 많이 진행됩니다.
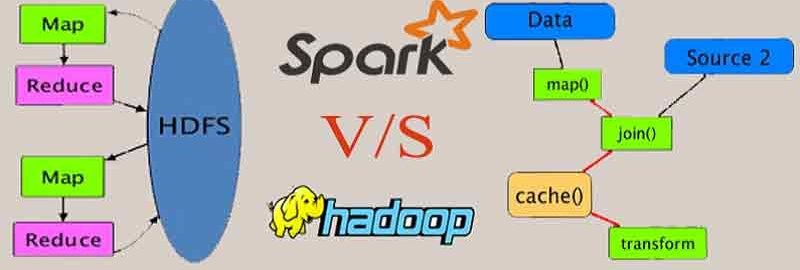
HDFS는 HaDoop File System의 약자입니다.
하지만 스파크의 경우 보조기억장치에 저장하는 것이 아니라 주기억장치 RAM에 계속 저장시키고 있기 때문에 연산이 무척 빠릅니다. 카드를 섞는데 한가지 섞고 내려놓고 다시 들어서 하는 작업이 아닌 한 번에 다 들고 섞는다고 이해하시면 됩니다.
두 번째로 스파크는 함수형 언어인 Scala를 주 언어로 사용하기 때문에 게으른(lazy) 연산이 가능합니다. 예를 들어 “1+1을 하세요.”라고 명령어를 입력하고, 결과를 보여달라는 명령어를 전달하기 전까지는 연산을 진행하지 않고 마지막에 몰아서 모든 연산을 마칩니다. 그렇기 때문에 속도에서 더 이점이 있을 수 있습니다. 다시 말하면 불필요한 연산을 좀 더 줄일 수 있습니다.
세 번째로는 다양한 언어를 지원하여 빅데이터에 입문하신 분들도 쉽게 쓸 수 있습니다. 주 언어는 Scala로 되어 있지만, Scala는 JVM(Java Virtual Machine) 위에서 동작하는 프로그래밍 언어이기 때문에 java와 호환이 아주 잘 됩니다. 그 외에도 python이나 R로 프로그래밍을 하면 다시 bytecode로 변환 시켜, JVM 위에서 작동할 수 있게 만들어 줍니다.
프로세스 마이닝에서 데이터 전처리가 왜 필요하고 그걸 위한 툴인 스파크에 대해서 개략적으로 살펴보았습니다. 스파크는 전처리에도 훌륭한 도구이지만 그 외에도 Spark SQL Spark Streaming Spark ML, GraphX을 제공하며 빅데이터 계의 중심에 있습니다. 빅데이터, 머신 러닝과 같이 최근 화두의 최신 기술을 익히고 싶다면 스파크에 관심을 갖는 걸 추천드립니다.
[참고]
http://sijoo.tistory.com/14
https://intellipaat.com/blog/hadoop-vs-spark-choosing-the-right-big-data-software/
