The Configuration of ProDiscovery System Introduction
Jaehwan Lee| Apr 25 2018|4 min read
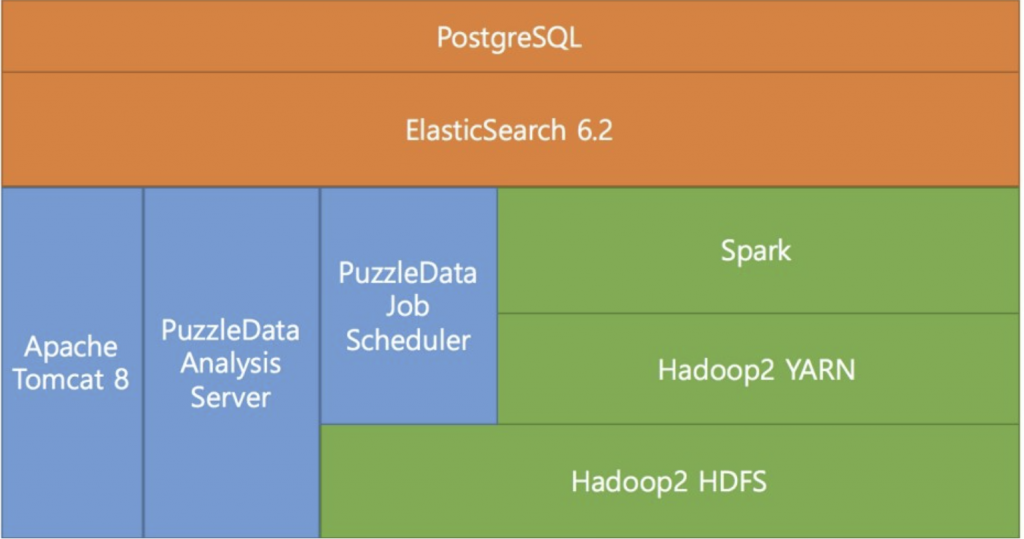
<ProDiscovery System Configuration>
ProDiscovery is designed with a complex system configuration to handle large-scale data processing and ensure fast data processing capabilities. Initially, all these configurations are set up on a single server. However, for processing large volumes of data, it is necessary to separate servers and configure multiple units.
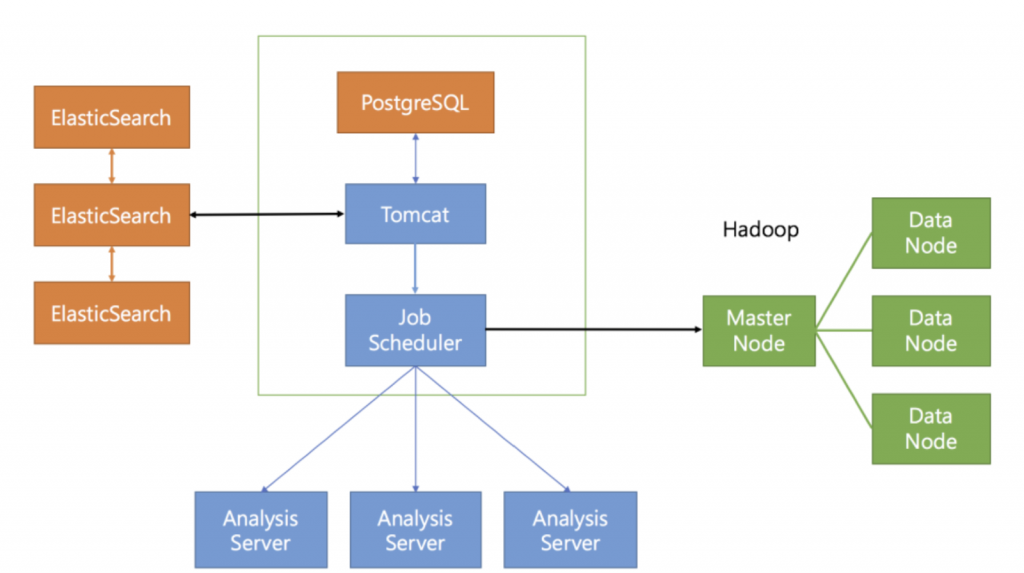
<Multi-Server Configuration for Big Data Processing>
To analyze data using ProDiscovery, it is necessary to preprocess the raw data that users possess into a format suitable for analysis. This preprocessing task is internally referred to as [Data Preprocessing].
<Data Preprocess>
To preprocess data effectively, it is crucial to handle substantial amounts of data. For this purpose, ProDiscovery utilizes Hadoop and Spark, the systems designed for big data processing. Let’s explore the specific roles of each system:
Hadoop HDFS
Hadoop HDFS serves as a data repository. It stores original event files (CSV) uploaded by users and can also store real-time data collected through data collection modules. Moreover, it enables distributed data processing across multiple servers when performing preprocessing tasks via Spark.
Hadoop YARN
Hadoop YARN manages server resources. It monitors various server resources within the Hadoop system and allocates resources for preprocessing tasks whenever requests are received, ensuring efficient processing.
Spark
Spark performs the essential task of generating analyzable data from the original event data. All preprocessing-related code is written and executed here. It operates in conjunction with Hadoop, enabling high-speed, in-memory analysis.
Job Scheduler
The Job Scheduler oversees data preprocessing and analysis request tasks. When a data preprocessing task is requested, it dispatches the job to Spark and monitors its progress. It also manages algorithm computation requests from puzzles.
Analysis Server
The Analysis Server executes algorithm computation tasks requested by various puzzles, ensuring the smooth functioning of analytical processes.
Tomcat
Tomcat acts as a web server, handling incoming requests from browsers and delivering responses. It manages and processes elements displayed on the interface.
ElasticSearch
ElasticSearch stores analyzable data related to events and processes generated through data preprocessing. It delivers query results at lightning speed thanks to its memory-caching mechanism.
PostgreSQL
PostgreSQL manages all metadata, including folder information, dataset details, dashboard data, and user information, excluding actual data.
ProDiscovery efficiently processes data based on big data principles, integrating algorithms developed in-house onto well-established open-source systems. This approach has been validated by numerous users and businesses, ensuring reliable and effective data processing.
RPA and process mining, when combined, offer a holistic approach to automation, providing visibility and efficiency for businesses in the digital era.