

머신러닝에 필요한 데이터셋을 구하려면?
고원휘 | 5월 24일, 2018 | 5분읽기
Pro Discovery 2.0은 Process와 관련된 Insight을 제공해 줍니다.
하지만 Insight을 제공해주는 것에 그치는 것뿐 아니라
Machine Learning을 적용하기 위해 필요한 Data를 제공해 줄 수도 있습니다.
프로세스 마이닝은 Performance Analysis, Process Model 도출, Conformance Checking 등에 유용한 도구입니다. 과거의 Data를 분석하는 데는 유용한 도구이지만 여기서 한발 더 나아가 Data Mining과 연계한다면 더 유의미한 결과를 낼 수 있습니다. 어떻게 Process Mining과 Data Mining을 연계할 수 있는지 예를 들어서 설명해보겠습니다.
연구원 A는 국내 거대 제조업 S사에 Data Science Team으로 취업하였습니다. A의 첫 업무로 PI(Process Innovation)부서의 요청에 따라 Process 병목 부분을 분석하고, 중요 Process를 도출해내었습니다. 이때 유용한 도구로 Pro Discovery 2.0을 사용하였습니다.
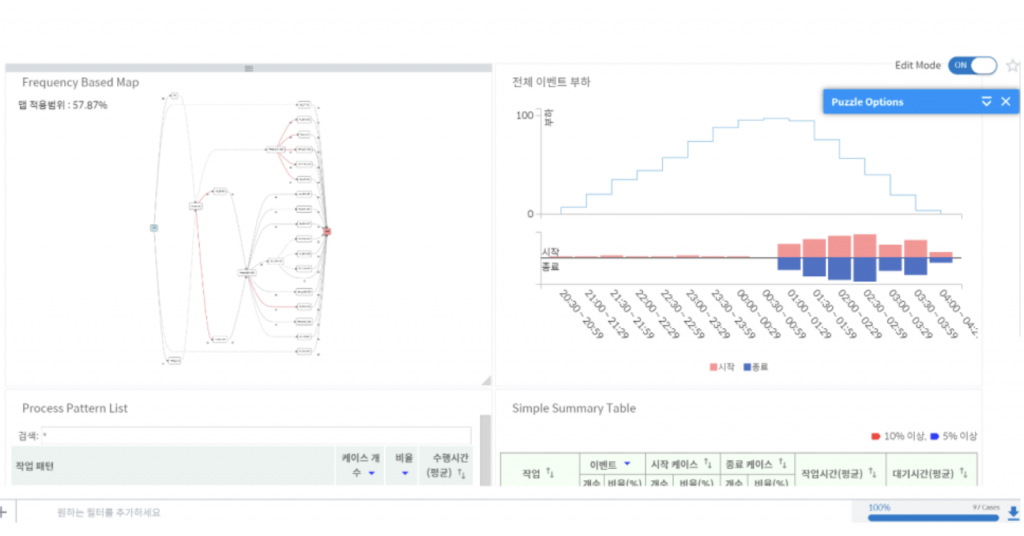
그러자 PI 부서에서 다시 요청이 왔습니다.
“과거의 프로세스에 대한 이해는 이제 충분하게 되었습니다. 머신러닝을 적용하여 프로세스 혁신에 대한 예측 시스템을 구축하고 싶습니다. 연구원님과 함께 프로젝트를 진행하고 싶습니다.”
이 요청을 받은 연구원 A는 고민에 빠졌습니다.
“Supervised learning을 해야 할 거 같은데… 어떤 알고리즘을 써야 하지? 아니 일단 데이터 셋 구성하는 거부터가 일이네…”
연구원 A의 고민을 이해하기 위해선 Supervised learning에 대해서 이해를 해야 합니다.
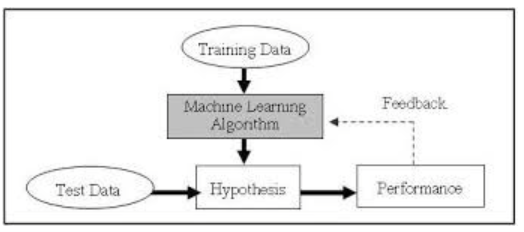
(출처 : Wikimedia Commons)
일단 Machine Learning이란 data X와 X에 대응하는 현상 Y에 대한 관계를 가장 잘 설명하는 함수 f를 찾는 것입니다. Training Data를 넣어 Machine Learning Algorithm에 따라 훈련을 합니다. 그리고 Hypothesis 중 관계를 가장 잘 설명하는 함수 f를 선택하고 Test Data를 통해 검증합니다.
연구원 A의 상황에 대입하여 본다면
1. 우선 프로세스에 관련하여 Data를 구해야 합니다.
2. 이 Data를 실제 현상과 매핑해야 합니다. 어떤 프로세스 경로를 따른다면 결과가 안 좋았다면 그 프로세스 경로에 관련된 data는 X가 될 것이고 안 좋은 결과는 Y로 매핑하는 식으로 데이터를 구성해야 합니다.
3. 다음은 매핑 한 data를 훈련용과 검증용으로 나누어 줍니다.
4. 적절한 Machine Learning Algorithm을 선택해야 합니다. 이 예에선 좋은 결과, 안 좋은 결과 이산적으로 결정한다고 했으니 의사 결정 트리나, SVM 등의 알고리즘이 사용될 수 있습니다.
5. 알고리즘에 따라 훈련을 통해 함수 f가 결정되었다면 다시 검증용 데이터로 Performance를 측정합니다. 이 과정을 가장 적절한 함수 f를 찾을 때까지 반복합니다.
연구원 A의 고민은 가장 처음 Data와 관련된 고민이었습니다. 예측 시스템을 구축하기 위해선 일단 프로세스와 관련된 Data를 구해야 하고 이 Data를 실제 현상과 매핑해야 합니다. 이때 Process Mining은 굉장히 유용한 도구가 됩니다. 이와 관련하여 앞선 칼럼인 프로세스 마이닝과 AI를 통한 프로세스 혁신(https://blog.naver.com/prodiscovery/221088085181)을 참조하시면 자세한 내용이 적혀져 있습니다.
그러면 Pro Discovery 2.0에선 어떻게 연구원 A가 도움을 받을 수 있을까요? 필터 기능과 이벤트 데이터 다운로드 기능을 적절히 이용하면 유용한 Data를 얻을 수 있습니다.
데이터 셋을 구성할 때 성과와 관련된 컬럼을 차원 유형으로 추가합니다.

필터 기능을 이용하여 성과가 좋은 프로세스와 성과가 나쁜 프로세스 등을 구별하여 각각 구성합니다.
오른쪽 하단 위치한 이벤트 데이터 다운로드 기능을 이용하여 각각의 프로세스 정보를 받습니다.
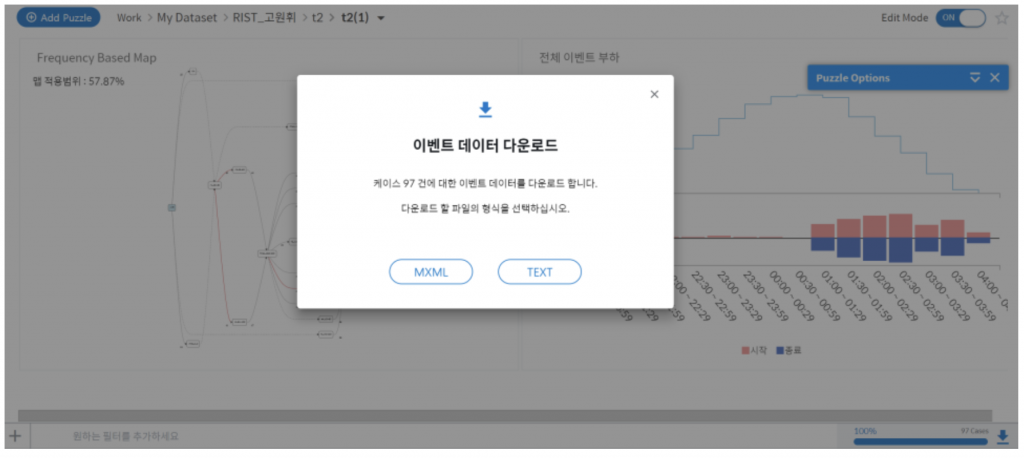
Text 형태로 Pro Discovery에서 전처리한 Data set을 얻을 수 있습니다.
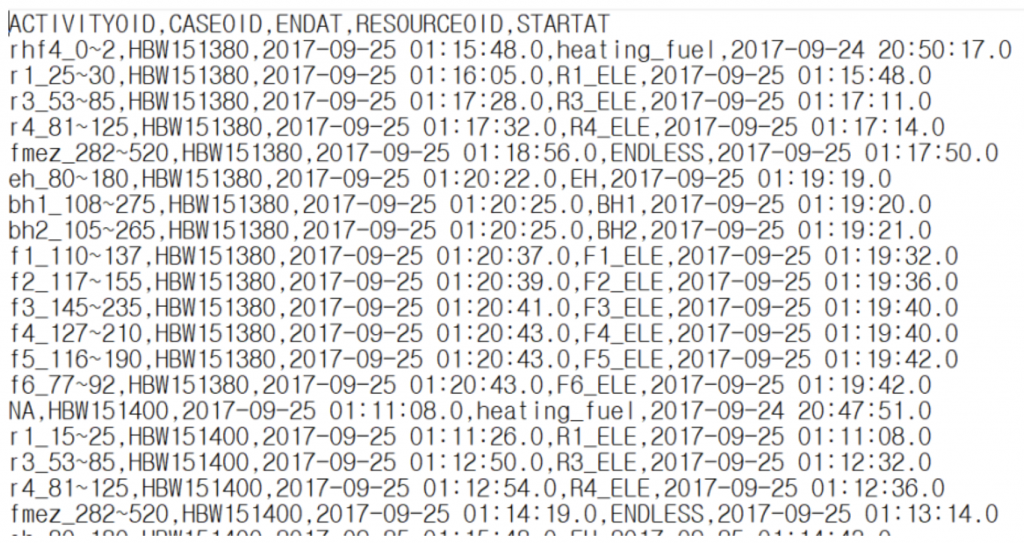
이제 연구원 A는 프로세스와 관련된 Data를 얻게 되었습니다.
Pro Discovery 2.0은 Process와 관련된 Insight을 제공해 줍니다. 하지만 Insight을 제공해주는 것에 그치는 것뿐 아니라 Machine Learning을 적용하기 위해 필요한 Data를 제공해 줄 수도 있습니다.